Accelerate 第1版(以下単にAccelerateと呼ぶ)はDevOpsに関するトレンドを抑えるうえで基本となる本なのですが、もはや古く最新の知見が書いてあるとは言えません。State of DevOpsは毎年アップデートされているのですがコンテキストを丁寧には抑えてくれず、背景を含めて読み解くのが難しいという印象があります。どうもAccelerate 第2版がそろそろ出るらしいんですが、とりあえず現時点での自分の理解をまとめておきます。
ここで面白いのが、Total cost of downtime per yearはローパフォーマーが最も安いという点です。ということは障害由来の損失を減らしたいなら、デリバリ回数を減らして慎重に評価するべきということでしょうか?もちろんそうではなくて、2021年のPuppetのState of DevOps Reportでは以下のように強調されています:
The result of all this is that those organizations that claim to be discouraging risk are actually following practices that increase risk, and many of their existing practices around risk management of infrequent deployments are simply risk management theater, when repeatedly, the data has shown that the use of continuous delivery practices predicts higher IT performance, and highly evolved respondents have higher levels of throughput and stability. In 2021, there’s virtually no rational argument for not adopting continuous delivery practices.
ハイパフォーマーが必ずしも不具合やトラブルのないチームを意味しているわけではないことにも注意が必要です。前述の通り、Total cost of downtime per yearなどいくつかの指標ではローパフォーマーが(局所的とはいえ)優れていることもあります。ハイパフォーマーを目指しますと錦の御旗を立てたあとで「前よりUI変更や障害に起因する対応が増えた、パフォーマンスが落ちているのでは?」という疑問が提起されるシナリオは回避したいところですし、人命に影響するシステムなどでは特に何をどこまで変えられるか・何が譲れないのかをしっかり見つける必要があるでしょう。
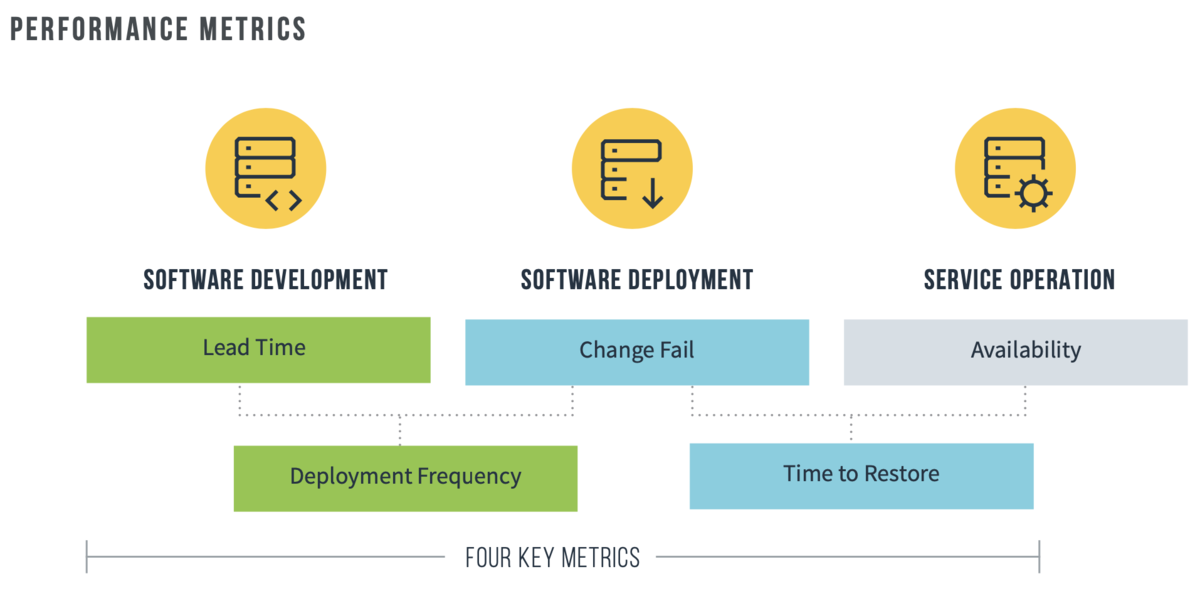
またこの研究ではソフトウェアと言いつつもアプリケーションやウェブサービス開発を前提にしている節があります。例えばFour Key Metricsの定義ではFor the primary application or service you work onという表現が使われています。ミドルウェア、デーモン、組み込みなどこの定義から外れるかもしれないソフトウェアに適用する場合は、各研究の前提に注意を払う必要があると思います。
個人的にはアプリケーションやウェブサービス開発においても、歴史ある資産の運用保守には直接適用できないことがあると思います。そうしたプロジェクトでは組織パフォーマンスではない「別のもの」を大切にすることがしばしばあるからです。それでも法対応や脆弱性対応を考えると高速高頻度なデリバリは必要になることも多いはずですが、結局のところビジネス要件しだいというやつです。
まとめ
AccelerateとState of DevOpsレポートを基にすることで、一定の信頼性と普遍性が担保されたプラクティスを学ぶことができます。
そしてDevOpsの問題意識として、運開分離や承認プロセスを重んじてきた慣習を見直し、高頻度のデリバリー、リスク管理のアプローチの変化、そして軽量プロセスへの移行こそが大切だという変遷を見ることができます。
自組織への適用には注意を要するところもありますが、どのようなベストプラクティスでもそのようなものなので、少しずつでも取り入れてみてはいかがでしょうか。


")
 (ビッグコミックス)")
")

")