Accelerate 第1版(以下単にAccelerateと呼ぶ)はDevOpsに関するトレンドを抑えるうえで基本となる本なのですが、もはや古く最新の知見が書いてあるとは言えません。State of DevOpsは毎年アップデートされているのですがコンテキストを丁寧には抑えてくれず、背景を含めて読み解くのが難しいという印象があります。どうもAccelerate 第2版がそろそろ出るらしいんですが、とりあえず現時点での自分の理解をまとめておきます。
端的に言うと、これらは安定したソフトウェアを高速に顧客に提供できる良い開発チームの特徴を踏まえ、皆さんの組織で再現可能にするための研究であり指針です。当然「良い開発チームがあれば常に良い問題解決ができる」というわけでも「ここで定義された良さが組織問わず普遍的である」というわけでもありませんが、顧客の課題に立ち向かうための組織設計において良い仮説を提供してくれるはずです。
「こんにちのソフトウェア開発組織はどうあるべきか」を示す研究
Accelerateでは24個のケイパビリティ(組織全体やグループとして保持する機能や能力)を提唱しており、それらの実践を推奨しています。これらのケイパビリティは以下のカテゴリに分類されます:
- 継続的デリバリ
- アーキテクチャ
- 製品とプロセス
- リーン思考に基づく管理と監視
- 組織文化
State of DevOps Reportはこの流れを汲み、ハイパフォーマーは何をして、結果として何を得ているのか?ハイパフォーマーに近づくために何をすべきなのか?を明確にしています。Exective Summaryをざっとまとめると以下のような要素を深堀りしています:
- 2018: クラウド、OSS、組織文化、アウトソーシングなどの組織戦略など
- 2019: 人材育成によるハイパフォーマーの増大が可能であること、デリバリ速度や安定性が組織目標達成率に影響すること、レガシーな変更承認プロセスの問題など
- 2020: 組織内プラットフォームの重要性、変更管理プロセスのあり方など
- 2021: SREの重要性、中間層からの脱出、ドキュメントのDevOpsケイパビリティへの貢献
- 2022: ソフトウェアサプライチェーン、組織パフォーマンスの要因
こうした深堀りにより、目指すべき理想のソフトウェア開発組織が高い解像度で抽象化されます。各組織が自己を見つめ直し変更点を見出すための道標として活用できる、鏡のような研究になっていると言えるでしょう。キモはこの研究が実際の数万もの組織を調査した結果を踏まえており、「ぼくのかんがえたさいきょうのそしき」でも「専門家が提唱する10年後の働き方」でもない「既に実現されている未来」が書かれている点です。書かれている内容には一定の信頼性と普遍性を期待できます。
またSoftware Delivery Performanceを示す指標であるFour Keys Metricsに、Operational Performanceを示すFifth MetricsであるReliabilityを加えて、Software Delivery and Operational (SDO) Performanceを継続的に評価し改善することが重要であると述べています。これもまた自組織をどう変えていくかを議論するための良い道標となるでしょう。
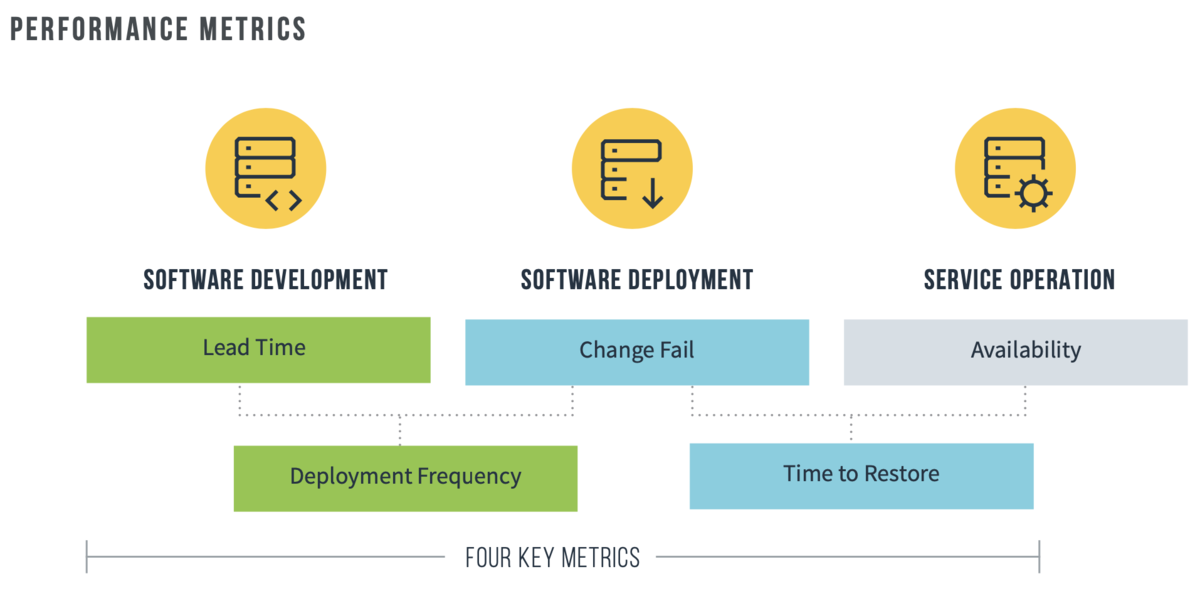
アウトソーシングや組織パフォーマンスなど、経営や組織設計に向けた研究内容も多いので、DevOps=デプロイ自動化と思っていると少し面食らう内容かもしれません。この研究は「組織としてパフォーマンスを高めたければ組織設計に向き合うことが必要で、そのためには古い慣習を疑い継続的デリバリやアーキテクチャなどの技術を理解することが必要」だということを繰り返しデータを用いて述べるものです。もちろんDevOpsに関心のあるエンジニアにも役に立つのですが、どちらかといえば「なぜ組織のパフォーマンスが上がらないのか」に悩む経営にこそ役に立つ内容となっています。
DevOps現場における問題意識の移り変わり
継続的デリバリは本当に必要なのか
研究はまず「ソフトウェアのデリバリは組織のパフォーマンスを左右するのか」を疑うところから始まっています。結果的にこの仮説は証明され、例えば2016年のレポートには「ハイパフォーマーがソフトウェアのデリバリを高頻度に行っていて、結果として低い障害発生率と安い障害対応コストを実現している」という例が示されています。ここに相関関係が認められるのだから、高頻度デリバリが行えていない理由を見つけて潰していきましょうという話になります。

ここで面白いのが、Total cost of downtime per yearはローパフォーマーが最も安いという点です。ということは障害由来の損失を減らしたいなら、デリバリ回数を減らして慎重に評価するべきということでしょうか?もちろんそうではなくて、2021年のPuppetのState of DevOps Reportでは以下のように強調されています:
The result of all this is that those organizations that claim to be discouraging risk are actually following practices that increase risk, and many of their existing practices around risk management of infrequent deployments are simply risk management theater, when repeatedly, the data has shown that the use of continuous delivery practices predicts higher IT performance, and highly evolved respondents have higher levels of throughput and stability. In 2021, there’s virtually no rational argument for not adopting continuous delivery practices.
リスクを回避するためにデプロイを減らすアプローチは、むしろリスクを増やす結果に終わっている。今日において継続的デリバリをしない理由はない……という主張です。こうした傾向を数値で説明できるようになったのは、開発チームがあるべき姿を模索する人にとってとても重要な変化だと思います。
古典的な組織管理にテクノロジーで立ち向かう
リスクを減らすための工夫がむしろリスクを増やしている、というのはこのState of DevOps Reportで繰り返し指摘されています。のでマネジメントを長くやってきた人もけっこう興味深く読めるレポートになっていると思います。
例えば2019年にはフォーマルな変更管理システムについて掘り下げています。heavyweight change approval process(重量変更承認プロセス)とも呼ばれているこれは、承認委員会とかそんな感じの存在にお伺いを立ててソフトウェアに変更を加えていくというアプローチです。segregation of duties(職務分掌)を普通に実装しようとすると、実装する人と適用・運用する人との間でソフトウェアを受け渡す際に承認プロセスが入るのは自然なことだと思われます。
対してClear change process(軽量変更承認プロセス)というのはPull Requestのことです。変更内容に対してレビューをして承認しマージ(適用)するのですから、これもれっきとした変更管理だということですね。PRをマージした結果がいつどのように本番環境に適用されるのかを明確にする、すなわちデプロイパイプラインを自動化したり関連する監査ログを残したりする必要はありますが、日々の運用負担はかなり軽減されます。
この研究ではこの2つを比較して、Clear change processのほうが望ましいとしています。もちろん「簡単な方が楽だからこっちにしようぜ!」という単純な比較ではありません。Accelerate §7.2には4パターンの変更管理ポリシーを比較して、フォーマルなやり方ではFour Keysのうち変更失敗率には相関関係になく、残りの3つのメトリックには負の相関があることなどが示されています。フォーマルなやり方では目的を達成できず、むしろ承認プロセスが無いところにすらパフォーマンスで劣っているということが如実に示されているわけです。
承認プロセスとか運開分離とか、特に気にせずそういうものだとして入れてしまうところもあるとは思うんですが、こうした研究を踏まえて「同じ目標をより望ましい手段で達成できないか」考えてみるのはとても重要です。本研究は組織文化や技術プラクティスについても研究されており、様々はヒントを得られると思います。
注意するところ
本研究は「組織としてパフォーマンスを上げたければ、ソフトウェアのデリバリを改善する必要がある」という立場に立っています。自組織に本研究の知見を適用する場合、この前提がどこまで正しいのかは考えておいたほうが良いと思います。例えばUIの変更がエンドユーザーに混乱をきたしたりその教育にコストがかかったりする場合、デリバリ頻度を上げることでかえってエンドユーザーとのコミュニケーションコストが上がり、組織としてのパフォーマンスが低下することも考えられます。
ハイパフォーマーが必ずしも不具合やトラブルのないチームを意味しているわけではないことにも注意が必要です。前述の通り、Total cost of downtime per yearなどいくつかの指標ではローパフォーマーが(局所的とはいえ)優れていることもあります。ハイパフォーマーを目指しますと錦の御旗を立てたあとで「前よりUI変更や障害に起因する対応が増えた、パフォーマンスが落ちているのでは?」という疑問が提起されるシナリオは回避したいところですし、人命に影響するシステムなどでは特に何をどこまで変えられるか・何が譲れないのかをしっかり見つける必要があるでしょう。
もちろんこうした場合でも、Feature ToggleやKeystone Interfaceによって高頻度デプロイと安定したUIの実現は可能です。また「対応が増えた」のは「今まではまとめて起こっていた問題が散発的に出るようになっただけで、個々の解決はむしろ楽になっている」可能性もあります。ここで言いたいのはこうした仕組みを用意する必要性に先んじて気づきたいですねという話、関係者の期待値調整をあらかじめしておきたいですねという話です。
またこの研究ではソフトウェアと言いつつもアプリケーションやウェブサービス開発を前提にしている節があります。例えばFour Key Metricsの定義ではFor the primary application or service you work onという表現が使われています。ミドルウェア、デーモン、組み込みなどこの定義から外れるかもしれないソフトウェアに適用する場合は、各研究の前提に注意を払う必要があると思います。 個人的にはアプリケーションやウェブサービス開発においても、歴史ある資産の運用保守には直接適用できないことがあると思います。そうしたプロジェクトでは組織パフォーマンスではない「別のもの」を大切にすることがしばしばあるからです。それでも法対応や脆弱性対応を考えると高速高頻度なデリバリは必要になることも多いはずですが、結局のところビジネス要件しだいというやつです。
まとめ
AccelerateとState of DevOpsレポートを基にすることで、一定の信頼性と普遍性が担保されたプラクティスを学ぶことができます。 そしてDevOpsの問題意識として、運開分離や承認プロセスを重んじてきた慣習を見直し、高頻度のデリバリー、リスク管理のアプローチの変化、そして軽量プロセスへの移行こそが大切だという変遷を見ることができます。 自組織への適用には注意を要するところもありますが、どのようなベストプラクティスでもそのようなものなので、少しずつでも取り入れてみてはいかがでしょうか。